来源:admin 发布时间:2022-05-30 浏览:165

行列式降解是企图在协作过滤器共现行列式的基础上,采用更浓密的隐矢量则表示采用者和贵重物品,发掘采用者和贵重物品的暗含浓厚兴趣和暗含特点, 在很大某种程度上填补协作过滤器数学模型处置浓密行列式潜能严重不足的难题。科耳草是把共现行列式降解成采用者行列式Q和贵重物品行列式P相加的方式,这时假如预估某一采用者u对某一贵重物品i的评分, 间接就能获得, 其中
和
是采用者u和贵重物品i的隐矢量,而自学隐矢量的操作过程他们是先乱数调用三个模块行列式Q和P, 接着依照已近评分的值求经济损失, 透过势能上升一步棋一步棋的预览模块获得的。
下面那个隐矢量的自学操作过程, 在广度自学中, 就能看作是三个单纯的数学模型则表示, 采用者矢量和贵重物品矢量能看作embedding的方式, 而最后的评分值(预估值), 是采用者矢量和贵重物品矢量范数后的相近度。 而这步范数演算, 就能看作三个脊髓模块里头的排序了。
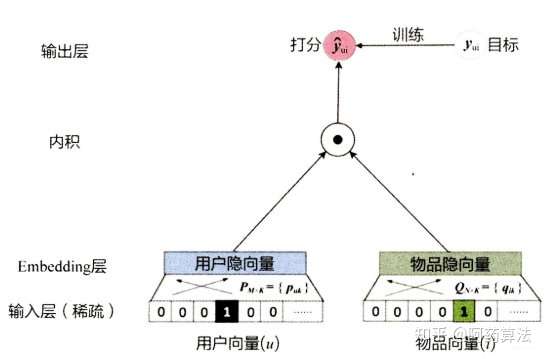
但那个数学模型由于内部结构太单纯,排序也太单纯, 使输入层难以对最终目标进行有效率的插值。 在前述难题中, 会辨认出常常数学模型会出现欠插值的状况
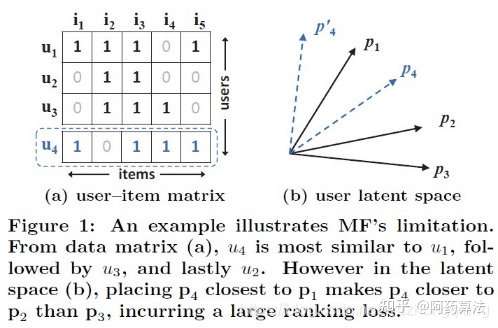
左图中, 右边的是他们说的共现行列式(user-item)行列式, 检视那个行列式,能排序出,
,
和
间的相近度。 会辨认出相交行列式里头
和
最相近, 其次是
,最后是
。 但假如他们把
,
,
用隐矢量的方式表现出来, 右图, 其中
是
的隐矢量。 会辨认出
和
挺相近, 而和
的相近度就小一些(不如
)。But, 假如此时他们想把
画出来,由于
离
最近,那么无论是虚线里头的哪种情况,都会辨认出
和
比
和
的相近度要大, 这在右边是不成立的。 也是说隐空间中,对于
来说, 右边的这种相近关系没法具体在隐空间中则表示出来。
直观的看,是隐矢量排序相近度的时候存在难题,因为相近度是夹角衡量的,夹角关系在降维之后有可能发生了错乱,但这间接的说明了单单采用范数足以可信的预估评分。所以为了更好地自学采用者和商品的隐矢量与评分间的关系,基于广度自学网络,作者想出了用三个多层的数学模型来替换单纯的范数演算来增强数学模型的自学潜能,那个是Neural CF的框架了。
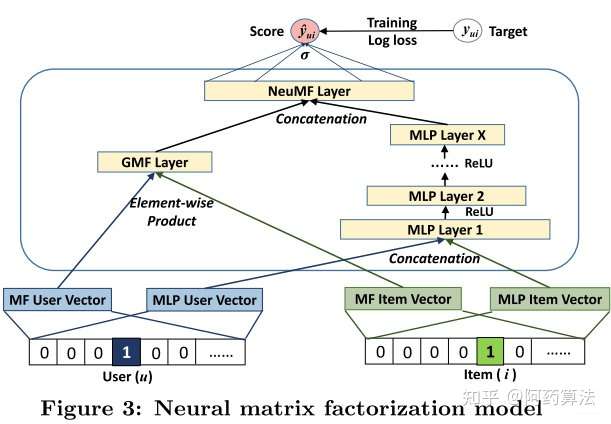
NeuralCF用多层数学模型+输入层的内部结构替代了行列式降解数学模型中的单纯范数操作。
其中原始的行列式降解采用范数让采用者与贵重物品交互,为了进一步棋让矢量在各维度上进行充分交叉,能透过元素积(三个长度相等的矢量对应维度相加获得另三个矢量)的方式进行互操作,这是广义的互操作方式。
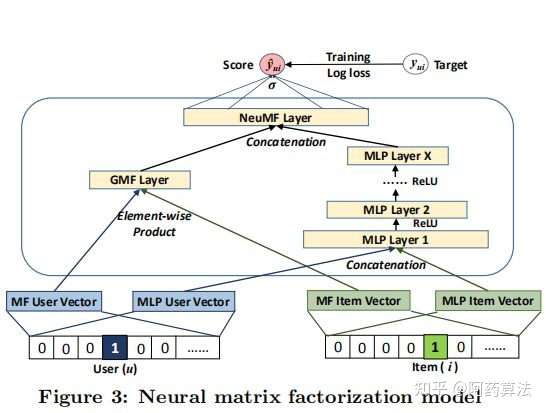
NeuralCF混合数学模型整合了原始NeuralCF数学模型和以元素积为互操作的广义行列式降解数学模型,使数学模型具有了更强的特点组合和非线性潜能。
但由于NeuralCF是基于协作过滤器的思想进行改造的,并没有引入更多其他类型的特点,这无疑经济损失了很多信息
NeuralCF数学模型前述上提出了三个数学模型框架, 基于采用者矢量和贵重物品矢量这三个embedding层, 利用不同的互操作进行特点的交叉组合, 并能灵活进行不同互操作层的拼接。 这里能看出广度数学模型构建所推荐数学模型的优势—利用数学模型理论上能够插值任意函数的潜能, 灵活组合特点, 按需增加或者减少数学模型复杂度。
并不是数学模型越复杂、特点越多越好。首先要防止过插值的风险,接着常常需要更多的数据和更长的训练时间才能使复杂的数学模型收敛,需要在数学模型的实用性、实时性和效果间进行权衡。

![生化变态多功能 - [ 月光 ]](/static/upload/image/20220410/1649541116121190.jpg)
 立即下载
立即下载 在线购买
在线购买 订单查询
订单查询![透视追踪 - [ 荣耀 ]](/static/upload/image/20220410/1649538173246720.png)


